If you are into deobfuscation, and especially devirtualization, chances are very high that you have read or heard about lifting to LLVM IR as one approach. In a way, obfuscation can be thought of as compiler de-optimization and LLVM, with its many efficient optimization passes, can work great in de-obfuscating. However, most resources available are either very academic, super technical and as such inaccessible or simply skip the details of the lifting process and just describe pipelines in a high-level fashion, without showing any details or code. As someone new to this topic, I was confused by the different tools and frameworks, which each have different caveats, high learning curves or simply do not really work outside of specific PoCs.
So I decided to get my feet wet, stop reading and just do what I always do when I want to learn something new: start implementing something in the most naive way I can come up with. As such, this should be read more like a diary entry / devlog rather than a tutorial or intro to devirtualization.
I have written many virtual machines and reversed some custom VMs I encountered in different malware samples, but I usually just reversed the handlers, wrote a disassembler and analyzed the bytecode by hand. This works against simple malware unpacking VMs, but not if your target is protected with something like Themida or VMProtect. I always wanted to write a proper devirtualizer, so I pulled up a random VM crackme from tuts4you and went for it.
The plan was simple: I lift the virtualized bytecode to LLVM, optimize it, recompile it, and I have the original program, stripped of its virtualization layer.
I will not go into how to reverse custom VMs, what VMs are or explain LLVM in much detail. Here are some links that could be helpful if you are unsure about these topics
The crackme is a simple flag checker, in which the flag check logic is virtualized:
The goal is to reverse the VM and figure out the correct keys.
Virtualization based obfuscation
Very briefly, a custom virtual machine, as a means of software protection, can be thought of as simply an emulator for a fictitious (or real) architecture which executes some sort of program (the "bytecode"). The VM from this crackme is a typical stack-based virtual machine, which somewhat resembles the x86 architecture and is really very simple to reverse - if you have never reverse engineered a custom VM, this one is a great intro.
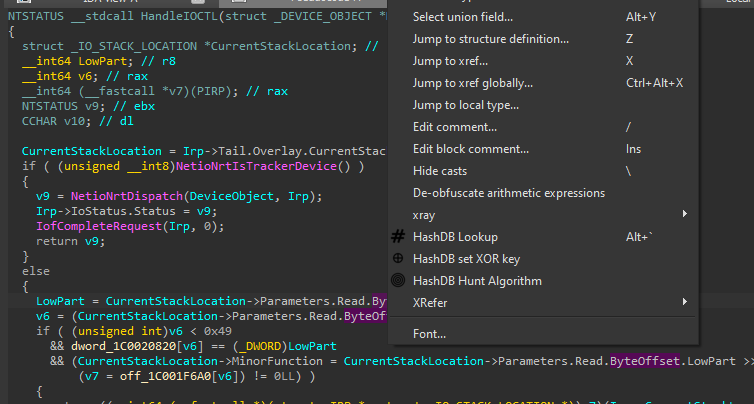
As mentioned earlier, the classic approach to reverse engineering a VM like this, is to find the entry of the VM and figure out its dispatch mechanism - usually either a fetch-decode-execute loop or a model where each handler dispatches to the next handler (which this VM does). Then you can parse each opcode handler and write a disassembler.
This blog however is not about this specific VM but about the lifting process, so I will just show an example of reversing one opcode.
Reversing VM Handlers manually
This is our VMENTER, the function which initializes the virtual machines registers and stack space by pushing the host stack:
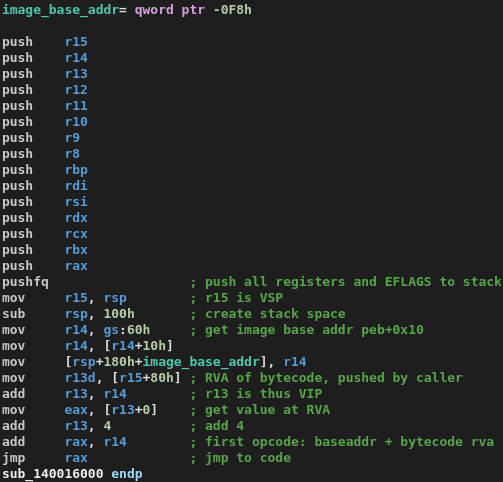
We now know already that R13 is the VIP (virtual instruction pointer), R14 the image base needed for RVA to real address calculations by the dispatcher later, and R15 our VSP (virtual stack pointer).
With this knowledge, reversing the PUSH_REG64 handler is very straightforward:
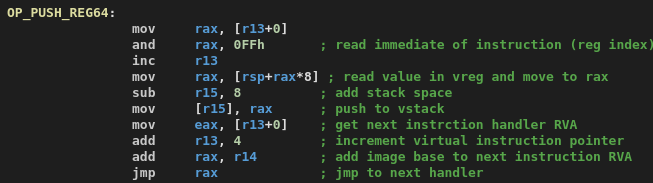
In this case, we can easily reverse all handlers manually pretty quickly because there is no obfuscation applied to the handlers at all.
Alternative: Using symbolic execution
Besides manually reversing the handlers, we can also use symbolic execution to run each handler and record how it transforms symbolic values we care about. In this case, I implemented it as an IDA script which executes the handler pointed to by the current cursor using the miasm framework and the IDA domain API.
We inferred from manual analysis that R13 is the VIP, R14 the image base and R15 our VSP, so I encode that in a pretty-printing method in the following script:
1 | from ida_domain import Database |
If we now run this on an example handler, in this case the one at 0x140016195, we get a dump of its symbolic effects in the IDA Python console:
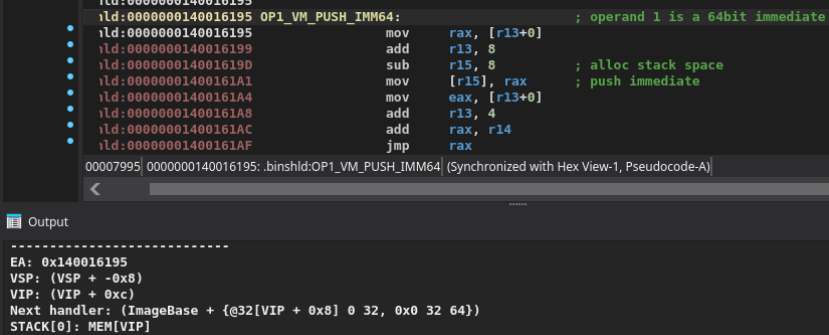
From this we can already infer enough meaning to figure out what the handler is doing:
- Instruction pointer increments by size of the instruction
- 8 bytes of memory pointed to by
VIPwere pushed to the stack (the immediate of the instruction) VSPadvances by 8 bytes
So this is a PUSH_IMM64 instruction, pushing a 64 bit immediate onto the stack!
The benefit of this approach is that we can now take these symbolic deltas and use them as signatures for the instructions. If we encounter this VM another time and it has some obfuscation applied, such as shuffled opcodes, we can simply symbolically execute each handler again and match them to the signatures to figure out each handler's meaning.
Once you have reversed all instructions and their opcodes you can write a bytecode parser, or rather, a disassembler for this VM. While there are more opcodes implemented in the VM, the following opcodes are those used by the bytecode, so the only ones we care about for this crackme. Names should be self explanatory:
1 | //===------------------------------------------------------------------===// |
On a side note, we could solve the whole crackme using symbolic execution, but that approach does not really scale for more complex and/or obfuscated VMs. We are interested in scalable workflows and actually devirtualizing the program, so let's start lifting.
Lifting to LLVM
I already mentioned that I was overwhelmed by the available lifting frameworks and lifters, which is why I decided to roll my own using the LLVM C++ API. Now, this was a bit of a headache to me: My plan was to lift each opcode to LLVM, so that I can run my disassembler and have it lift the virtualized bytecode program to a new LLVM program that I can compile and throw in IDA.
The general approach was thus to use the API to emit LLVM symbols manually, for example to load a value from a virtual register:
1 | llvm::LoadInst* reg_val = builder.CreateLoad(i64t, regs[reg]); |
With these building blocks I could then write an LLVM IR representation of each instruction such as PUSH_IMM64, JNZ and so on.
The basic pipeline looks as follows:
VM bytecode |
Now what caused me some headaches was how I should emulate the VM stack, if at all.
At first, I tried to offload the VM stack into the lifter itself instead of into LLVM. I had a std::vector of llvm::Value*s which I used to track which variable a current instruction references and inserted that variable. My idea was that I do not want the stack in the resulting
code, as it belongs to the VM, so I tried to keep it out of LLVM.
However, manually tracking values goes in the way of LLVM itself and broke its SSA form on many levels: If my lifter produced valid IR at all, it was badly optimizable and in many iterations the IR was completely broken. Optimization passes reason about the IR and have no insight into my external C++ bookkeeping - which prevented many of them from working correctly. By keeping part of the VM state hidden inside external C++ bookkeeping structures, I was effectively hiding semantics from the optimizer. Passes like dead store elimination, mem2reg and instruction combining could no longer reason correctly about value flow, because the actual dependencies only existed in my lifter and not in the IR itself.
After a while, I decided to stop doing this and implement the stack logic in LLVM IR as well. At first, this seemed counterintuitive to me: we are trying to strip the virtualization layer, in which the stack plays a part, so why would we implement it in our LLVM code?
MrExodia showed me how much I underestimated the power of LLVM optimization passes. If properly implemented, they can fold away the stack completely, leaving only the semantics we are interested in. You can see it in action with the following emulated
stack-based add operation:
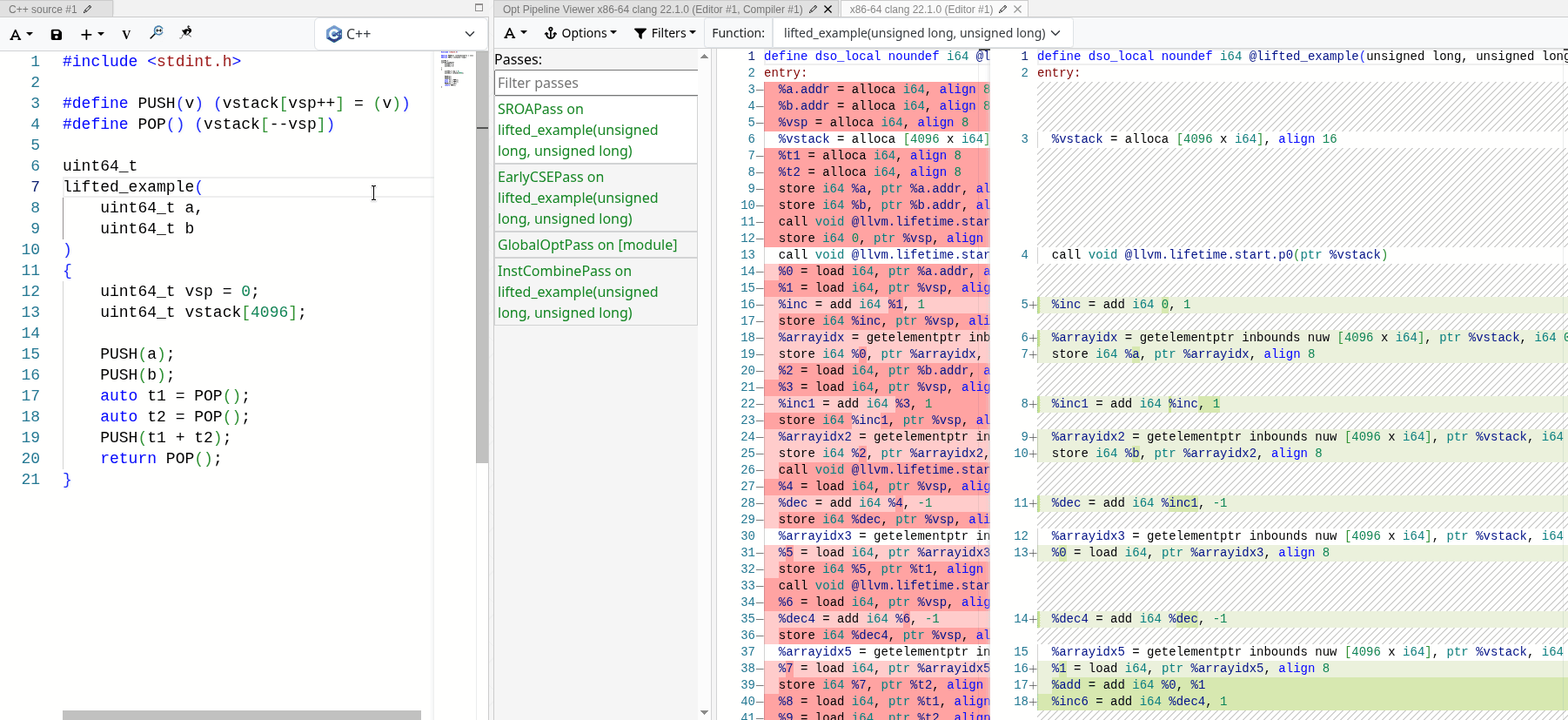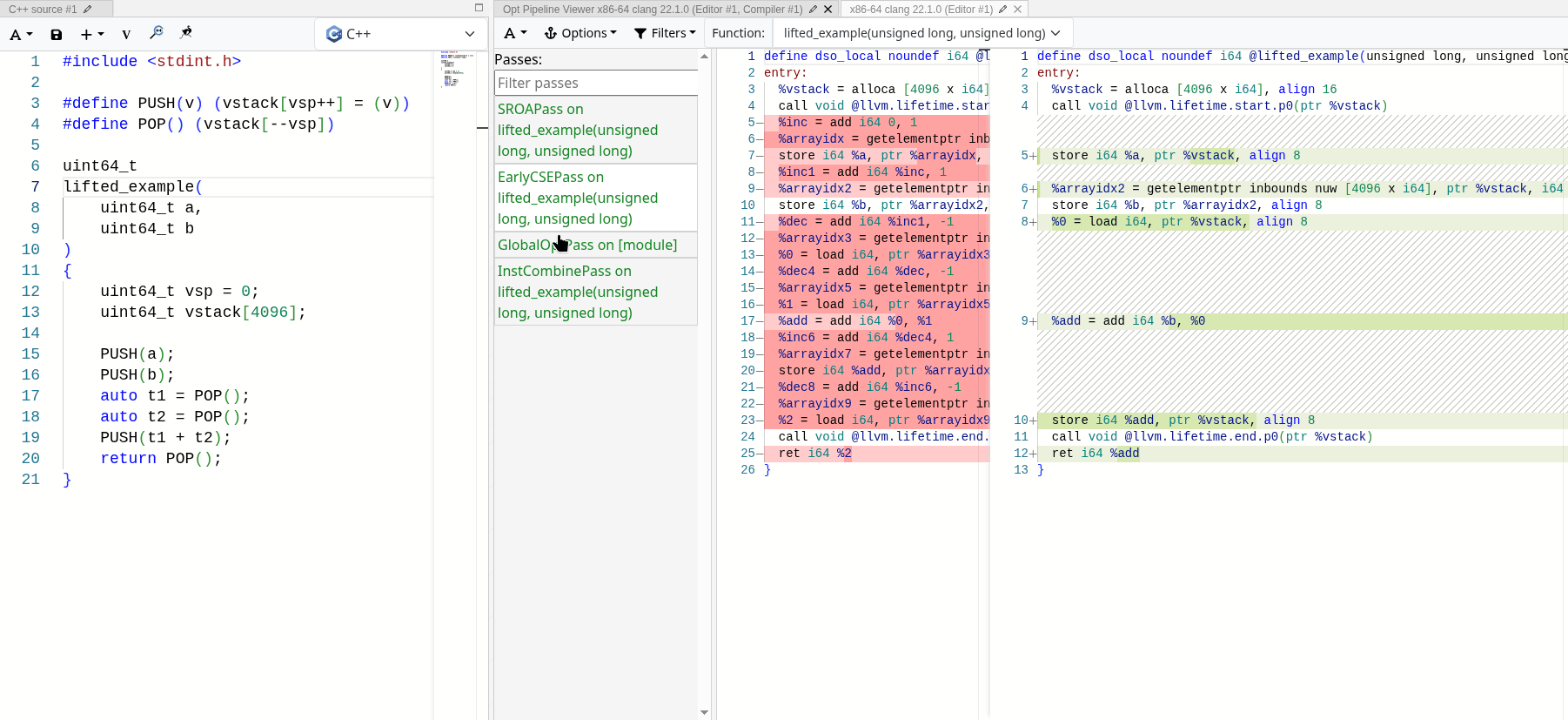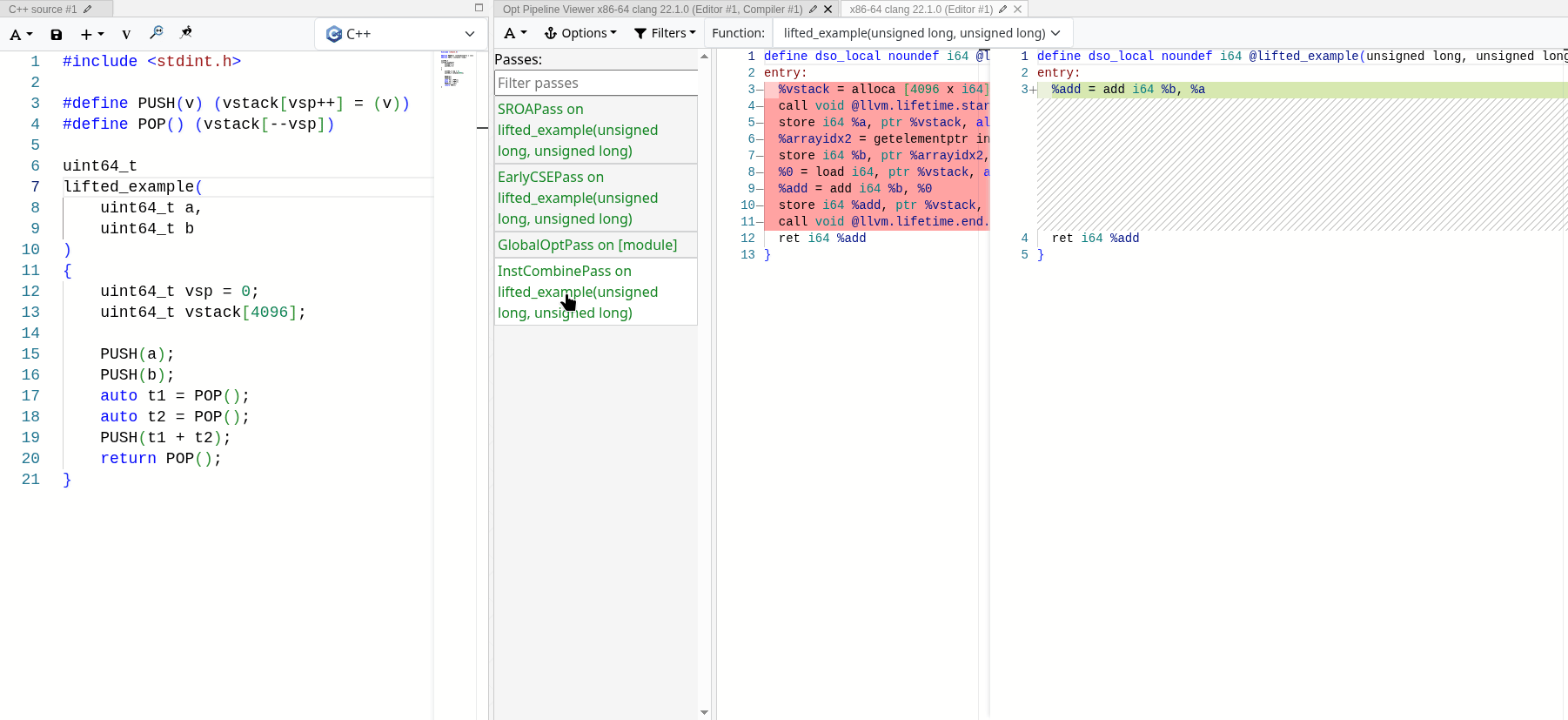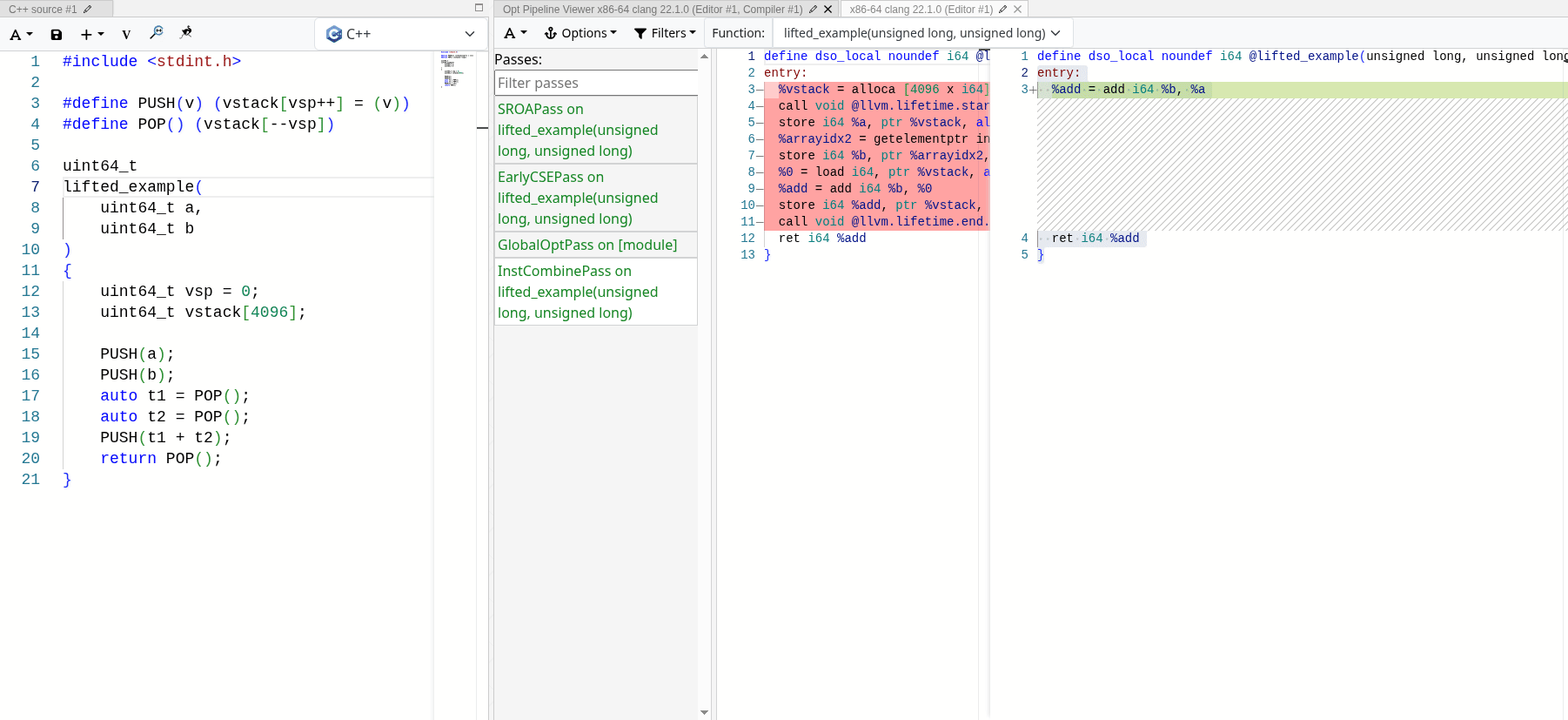
After all optimization passes, the only thing left is the actual operation, and the stack operations are stripped away completely. Since the stack accesses are all local and deterministic, LLVM can optimize it away and fold the emulated stack into SSA values.
Now knowing that I do not have to try to hide the VM stack from LLVM as it will be optimized away, I finished my implementation by implementing a lifting function for each opcode handler, which would emit the corresponding LLVM instructions.
You can view the whole code here.
Since this crackme only virtualized a single routine and had relatively simple control flow, I
modeled the entire bytecode program as one LLVM function, holding the input value as a
parameter, with multiple basic blocks. The stack is a simple memory array in a local variable,
VSP a pointer to it and the VM's registers are llvm::Value*s, which I hold in a vector in my
lifter, to make them accessible by index in my instruction lifters:
1 | // Flat byte array for the VM stack |
I then had to implement some stack management functions such as PUSH and POP:
1 | void Lifter::vm_push64(llvm::Value* value) |
Armed with these stack primitives, we can then model the different opcodes rather intuitively (this reminded me of emulator development, but just with a weird programming API)
1 | void Lifter::op_pop64(const uint64_t reg) |
Special care has to be given to the JNZ instruction, which is the only one that actually creates some control flow. To create basic blocks at jump targets, I implemented a two-pass lifting pipeline, where the first pass creates basic blocks at jump targets and for their "fallthrough" blocks (LLVM doesn't have fallthrough blocks in the classic sense, but only explicit jumps. We have to make fallthrough explicit):.
1 | // First pass: create basic blocks for JNZ targets and their fallthroughs |
In the second pass a big conditional statement in my disassembler loop then takes care to emit the respective LLVM IR belonging to the opcode:
1 | if (inst.name == "PUSH_REG64") |
The JNZ instruction simply links the basic blocks which were created in the first pass.
1 | else if (inst.name == "JNZ") |
After this lifting, we verify our function is valid IR using LLVM's llvm::verifyFunction API and run optimization passes on the resulting IR:
1 | void Lifter::optimize() |
Before optimization, the IR was about 8000 lines of stack shuffling and memory accesses:
1 | // [...] |
After -O1 optimizations, the full resulting IR became:
1 | ; ModuleID = 'byteshield_module' |
All that was left now was compiling the resulting .ll file to an executable with clang
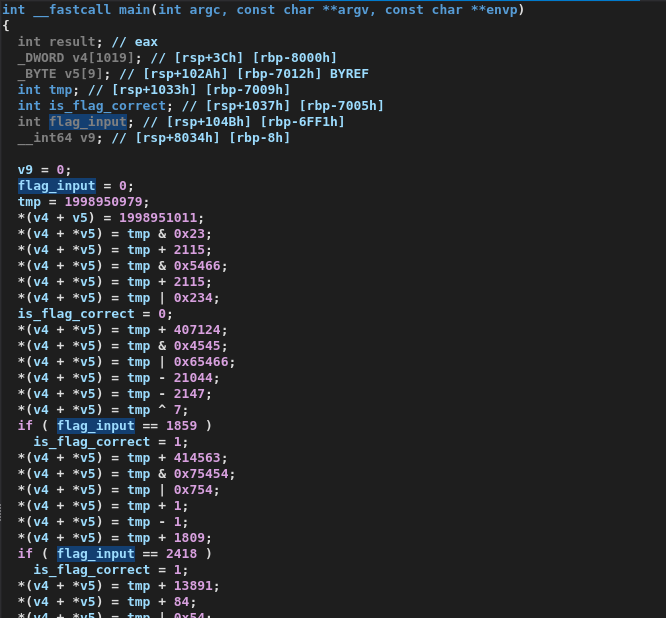
devirt.ll -o program. We fully devirtualized the bytecode! I could then analyze the devirtualized program in IDA, where all calculation logic was folded away so that only the flag checks remain:

One of my previous failed attempts showcased what the bytecode actually does. Most flags are hardcoded, except for one flag which depends on various arithmetic operations. (In my previous flawed approaches, this was not folded, as I failed to model the stack correctly):
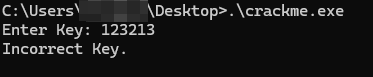
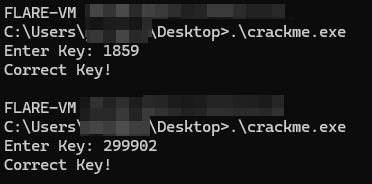
We can verify that we correctly cracked the crackme by testing the keys:
Outlook
As this was my first experience emitting LLVM IR, I learned quite a lot about how it is structured and some of its pitfalls.
The main thing to watch out for is making sure you emit your IR in a way that is both correct and optimizable, so that LLVM can work its optimization magic. Once the semantics are represented correctly in LLVM IR, LLVM's optimization passes can eliminate large parts of the virtualization automatically.
Devirtualization and lifting is fun. I suggest you give this crackme a try if you want.
Happy Hacking!